

Automatisering og personalisering er smart, men teknologien introducerer nogle faldgruber, som medierne skal holde øje med.
MediaWatch er i gang med en serie om personalisering i mediebranchen, og i den seneste artikel i serien har journalist Rasmus Lange talt med Henrik Frislev, der er data- og analysechef på Jyllands-Posten.
Artiklen handler blandt andet om, hvordan JP ser personaliserede anbefalinger som et vigtigt instrument i fastholdelsen af abonnenterne.
Det er en interessant artikel, som du bør læse, og den kommer også lidt ind på, hvilke typer af algoritmer, Jyllands-Posten bruger:
“Jyllands-Postens algoritme til personalisering er baseret på en teknik kaldet collaborative filtering. Metoden bruges til de såkaldte recommendere – altså lister med anbefalinger som eksempelvis ”læs også”-sektionerne.
Den filtrerer indhold ud fra både den enkelte brugers historik samt ud fra større mængder data blandt adskillige brugere.”
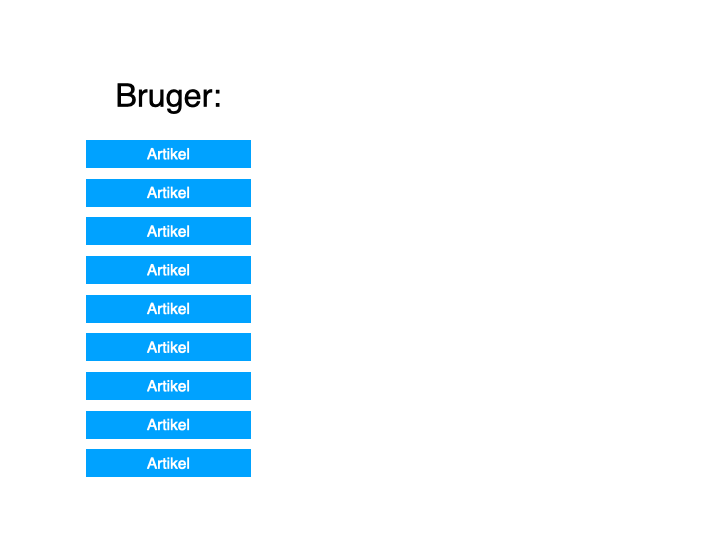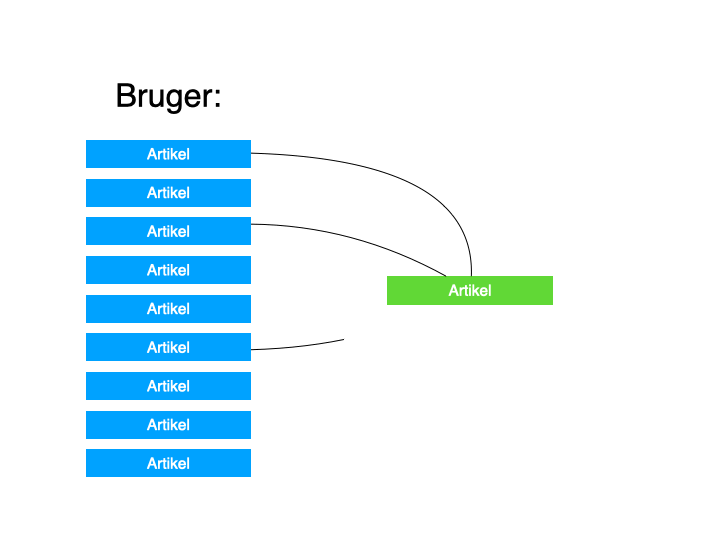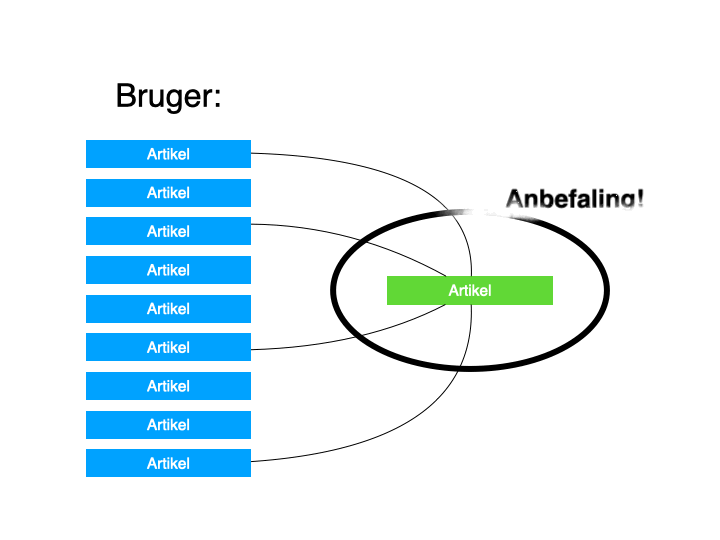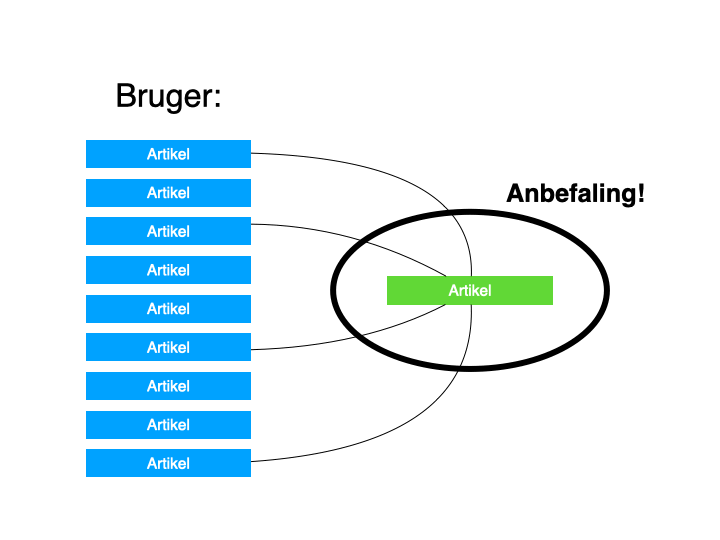
Kort fotalt, går collaborative filtering ud på, at maskinen kigger på hvilke artikler, den pågældende bruger har læst.
Den holder det så op imod, hvilke andre brugere, der har læst mange af de samme artikler, ellers har læst – og anbefaler så brugeren artikler, som mange af disse andre brugere har læst, men som den pågældende bruger endnu ikke har læst.
Når jeg har holdt oplæg om emnet, har jeg tidligere illustreret det på denne måde:
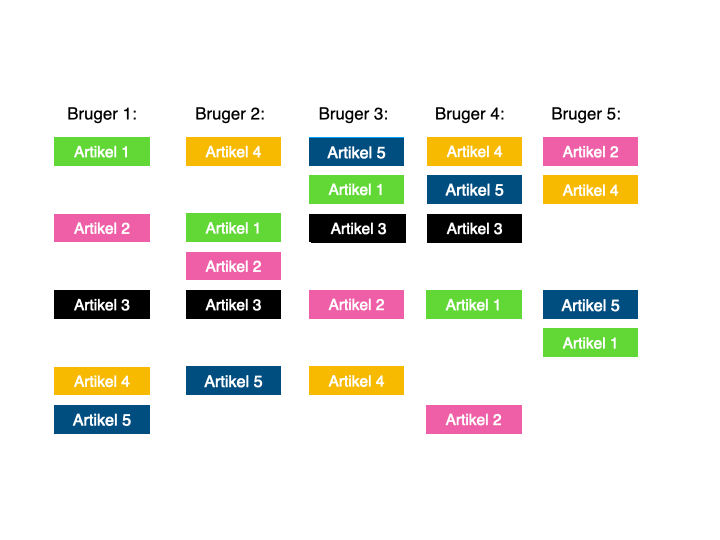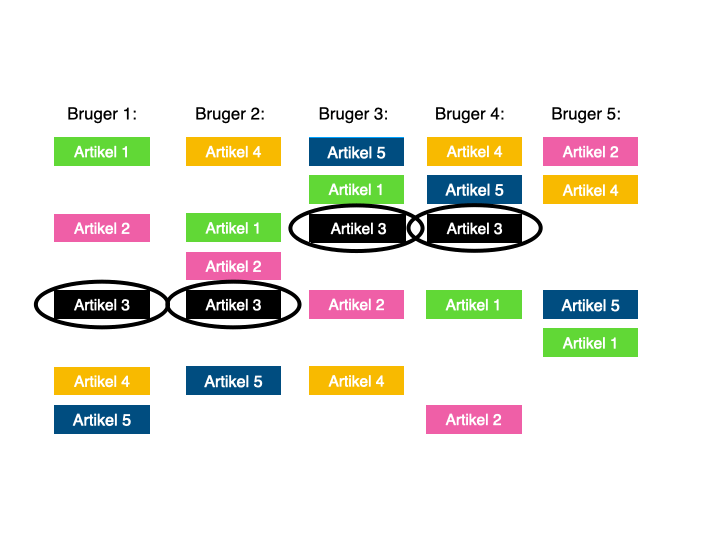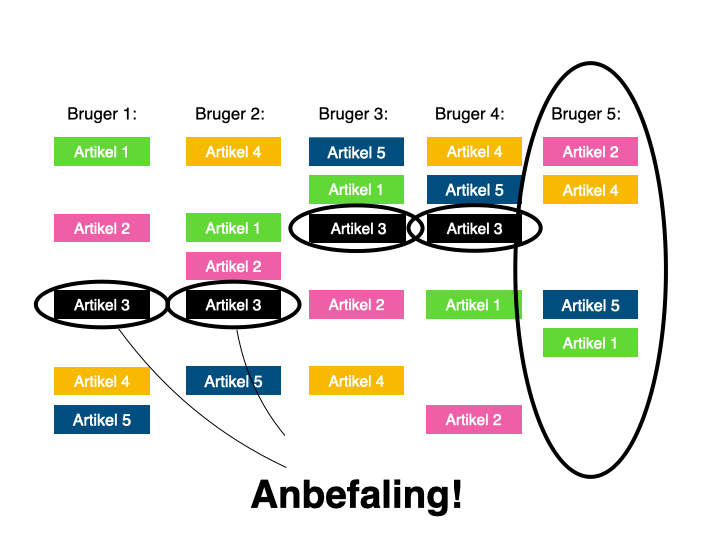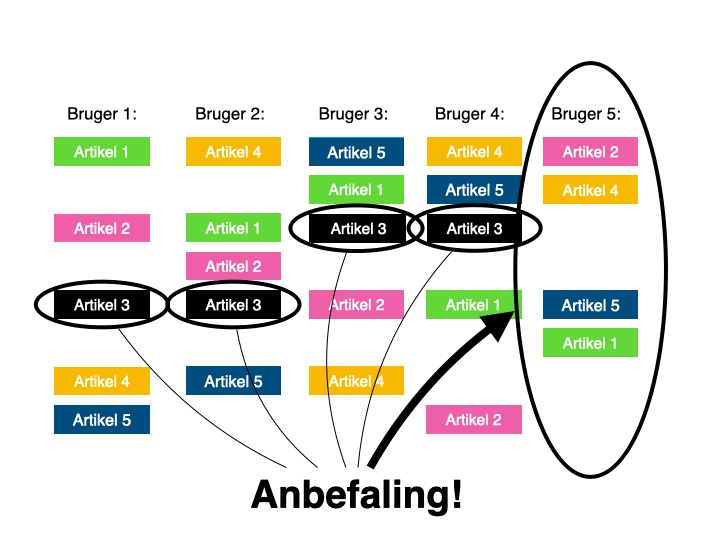
Det er smart og nemt at komme i gang med, fordi det ikke kræver indgående kendskab til ens eget indhold, da relationen skabes mellem brugere, og det er her, de potentielle artikelanbefalinger findes.
Der er dog også en iboende risiko forbundet ved den tilgang. Man risikerer nemlig at begrænse diversiteten i anbefalingerne:
“Studies have shown, some of them conducted by Hosanagar, that collaborative filters actually decrease diversity in what is being consumed. That is, it “pushes” people towards the same content. Content-based recommendations do not, it appears.
For a publisher this is critical if you discover that your recommendation algorithm is only emphasizing and pointing articles from certain categories – and thereby only a slice of the entire coverage – based on what the users click on.”
Kasper Lindskow fra Ekstra Bladet er en af dem i mediebranchen, der har mest viden og erfaring med anbefalingsalgoritmer, så læs hans tweet-svar til mig (og dette tweet) også.
Han bekræfter overordnet den forskel mellem de to former for anbefalingsalgoritmer, eller recommendersystemer som man også kalder dem, og den risiko der er forbundet med collaborative filtering.
Mennesker vs indhold
Nu er jeg hverken ansat ved Jyllands-Posten eller i besiddelse af et indgående kendskab til deres teknologi og opsætning, så jeg skal ikke sidde her og sige, at deres anbefalinger går i den fælde.
Men det er en reminder om, at man skal være opmærksom på, hvordan systemet udvælger anbefalingerne – og ikke kun, hvordan man præsenterer dem.
Jyllands-Posten eksperimenterer også med det, der kaldes content-based filtering. Som du måske kan gætte, er det her indholdet, der er i fokus og ikke de forskellige mennesker, der forbruger det.
Maskinerne kigger på de enkelte stykker indhold og finder relationer her, som bruges til anbefalinger til brugerne – ud fra, hvad den pågældende bruger allerede har læst.
Det kan illustreres på denne måde:
Her er risiciene mindre, mens kravene er større. For eksempel kræver det et vist kenskab til ens indhold at kunne lave de broer og relationer imellem artikler, der matcher “hvis du har læst X, bør du også læse Y”-kriteriet.
Her har Jyllands-Posten (ligesom mange andre medier) den udfordring, at indholdet endnu ikke bliver tagget eller beskrevet i et tilstrækkeligt omfang, kan vi læse i MediaWatch-artiklen.
Jeg har skrevet mere om nogle af de faldgruber, vi medier skal være opmærksomme på, når vi arbejder med automatisering. For eksempel kan det være afgørende, hvor åben og gennemsigtig man er omkring sine algoritmer – der skal helst være hverken for lidt eller for meget transparens, tyder det på.
Kræver det samtykke?
Et andet interessant spørgsmål, når vi taler automatisering, personalisering og anbefalinger er, hvordan brugerens forbrug bliver gemt – for uden det ingen anbefalinger.
Hvis en bruger er logget ind, giver det selvsagt mest mening at forsøge at gemme det på brugerens profil. Men hvis personen ikke er logget ind, må man kigge på for eksempel cookies som en løsning.
I oversigten over de cookies, jyllands-posten.dk sætter, finder vi denne blandt ‘Marketing’-cookie’erne – jeg antager, det må være til deres personalisering, men det kan kun en JP-ansat selvsagt bekræfte:
Det vil sige, at hvis Jyllands-Postens personalisering gør brug af denne cookie, så er der ingen personalisering, hvis brugeren ikke giver samtykke til Marketing-cookies – for eksempel hvis man vælger at afslå alt andet end de nødvendige cookies.
Men altså: Læs MediaWatch-artiklen, for det er et interessant indblik i, hvordan Jyllands-Posten går til et emne som personalisering, der på samme tid indeholder masser af potentiale og mange faldgruber.
Og måske er der også en artikel om Berlingske Media i MediaWatchs artikelserie, hvem ved..? 😉
Jeg udgiver også nyhedsbrevet Digital Ugerevy
Hvem skriver?
Mit navn er Lars K Jensen. Jeg er uddannet journalist og har arbejdet med digital udvikling i mediebranchen i en årrække. Jeg arbejder i dag med audience-udvikling i Berlingske-koncernen.
Jeg udgiver også nyhedsbrevene Digital Ugerevy og Products in Publishing.
Connect med mig på LinkedIn eller følg mig på Twitter, hvis du synes, emnet her er spændende.




